Building a Lightning-Fast Local AI Coding Assistant with DeepSeek and Ollama in VSCode
January 29, 2025

Table of Contents
- Table of Contents
- Introduction
- Why Choose DeepSeek R1
- Hardware Requirements
- Installation and Setup
- Configuration Guide
- RAG Capabilities
- Optimizing Your Workflow
- Troubleshooting
- Conclusion
Introduction
Local AI coding assistants have become increasingly powerful, offering performance that can match or exceed cloud-based solutions. This guide will show you how to create a high-performance coding assistant using DeepSeek models through Ollama, providing both instant code completion and intelligent chat capabilities in Visual Studio Code. Leveraging local infrastructure ensures zero latency, enhanced privacy, and full control over your development environment.
Why Choose DeepSeek R1
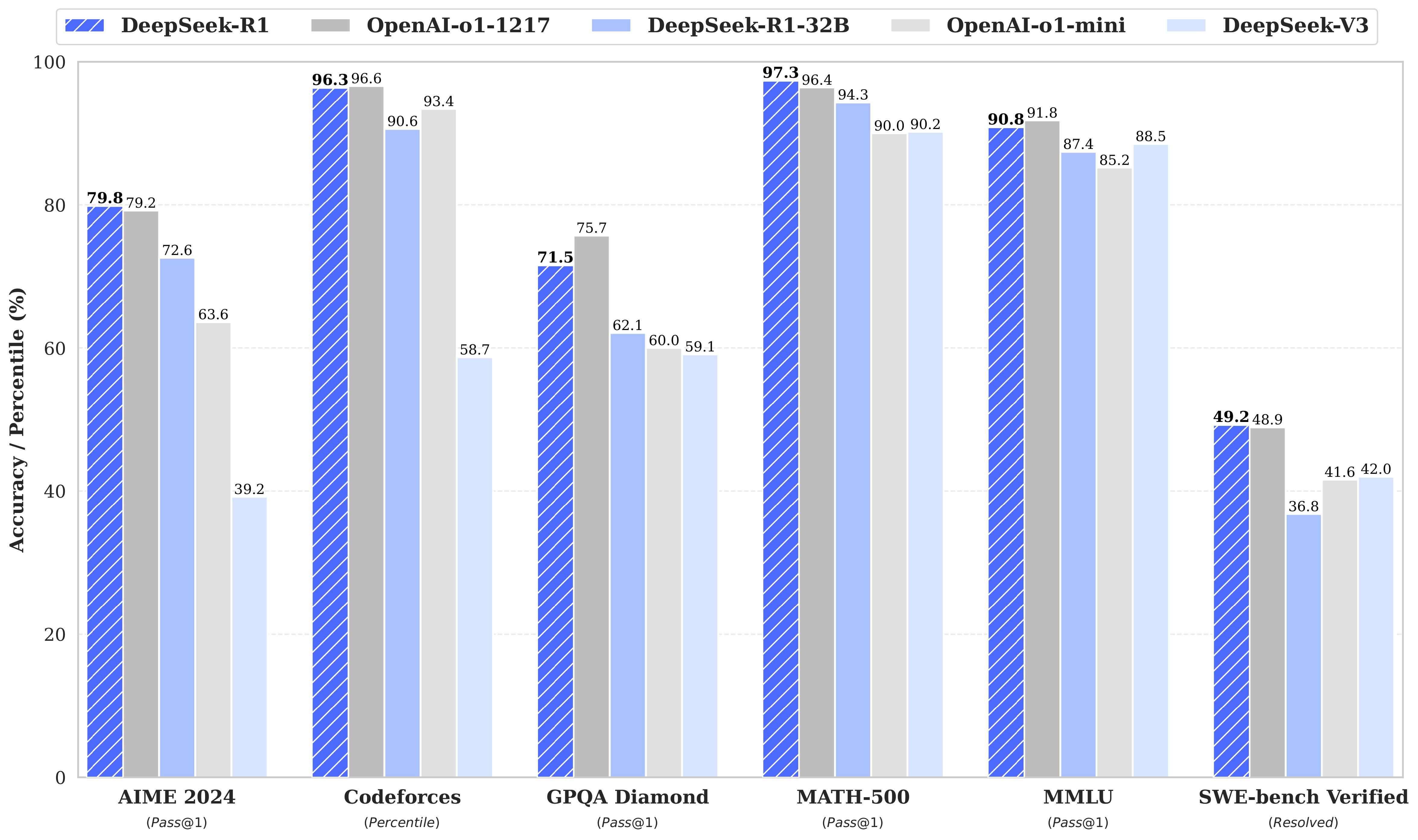 DeepSeek R1 model performance metrics (Source: Ollama)
DeepSeek R1 model performance metrics (Source: Ollama)
DeepSeek’s R1 series represents a significant advancement in local AI models, particularly excelling in coding and mathematical reasoning tasks. The model family includes various sizes to accommodate different hardware capabilities, from the efficient 1.5B parameter model to the powerful 671B version.
Key Benefits
- Complete Privacy for Your Code: Keep your codebase secure on your local machine.
- MIT License Allowing Commercial Use: Flexibility to use and modify the models in commercial projects.
- Strong Performance on Coding Tasks: Superior accuracy and context understanding tailored for development.
- Flexible Model Selection Based on Hardware: Choose models that fit your GPU capabilities.
- Advanced RAG Capabilities for Codebase Understanding: Enhanced retrieval-augmented generation to reference and understand your entire codebase.
- Zero Latency with Local Inference: Experience instant code completions without waiting for network responses.
Hardware Requirements
Model Size and VRAM Requirements
| Model | Parameters | VRAM Required | Storage | Recommended GPU |
|---|---|---|---|---|
| DeepSeek-R1 1.5B | 1.5B | ~3.5 GB | 1.1 GB | RTX 3060 12GB+ |
| DeepSeek-R1 8B | 8B | ~18 GB | 4.9 GB | RTX 4080 16GB+ |
| DeepSeek-R1 14B | 14B | ~32 GB | 9.0 GB | RTX 4090 x2 |
| DeepSeek-R1 32B | 32B | ~74 GB | 20 GB | RTX 4090 x4 or equivalent |
| DeepSeek-R1 70B | 70B | ~161 GB | 43 GB | A100 80GB x2 |
| DeepSeek-R1 (671B) | 671B | ~336 GB | 404 GB | Multi-GPU setup (e.g., NVIDIA A100 80GB x6) |
Source: GPU Requirements for 4-bit Quantized DeepSeek-R1 Models - APXML.com, 2025
Installation and Setup
Installing Ollama
macOS
Download the macOS installer from Ollama for macOS and follow the on-screen instructions to install.
Linux
Open your terminal and execute the following command:
curl -fsSL https://ollama.com/install.sh | sh
Windows
Download the Windows installer from Ollama for Windows and run the executable to install.
Installing VSCode Extension
- Launch Visual Studio Code.
- Access Extensions view by pressing
Ctrl+Shift+X. - Search for “Continue” and install the extension provided by Continue.dev.
Pull DeepSeek Models
Open your terminal and execute the following commands based on your GPU capabilities:
# For code completion
ollama pull deepseek-coder:1.3b
# For chat (choose based on your GPU)
ollama pull deepseek-r1:8b # or 14b for more powerful systems
Configuration Guide
Create a comprehensive configuration for your local AI assistant by editing the config.json file. Here’s a complete example optimized for DeepSeek models:
{
"models": [
{
"title": "DeepSeek Chat",
"provider": "ollama",
"model": "deepseek-r1:8b",
"contextLength": 8192,
"systemMessage": "You are an expert programming assistant. Provide clear, concise, and accurate responses."
}
],
"tabAutocompleteModel": {
"title": "DeepSeek Coder",
"provider": "ollama",
"model": "deepseek-coder:1.3b"
},
"embeddingsProvider": {
"provider": "ollama",
"model": "nomic-embed-text",
"maxChunkSize": 512,
"maxBatchSize": 10
},
"tabAutocompleteOptions": {
"debounceDelay": 150,
"maxPromptTokens": 2048,
"multilineCompletions": "always",
"disableInFiles": ["*.md", "*.txt"],
"useFileSuffix": true
},
"completionOptions": {
"temperature": 0.2,
"topP": 0.95,
"frequencyPenalty": 0.1,
"presencePenalty": 0.1,
"maxTokens": 2048,
"keepAlive": 3600,
"numThreads": 8
},
"ui": {
"codeBlockToolbarPosition": "top",
"fontSize": 14,
"codeWrap": true,
"showChatScrollbar": true
}
}
RAG Capabilities
The setup includes powerful Retrieval-Augmented Generation (RAG) capabilities that allow the AI to understand and reference your entire codebase. Here’s how to leverage them effectively:
Basic RAG Commands
@Codebase- Search the entire codebase.@filename- Search specific files.@docs- Search documentation.
Example Usage
> @Codebase How does our authentication system work?
> @src/auth/* What are the security measures in place?
> @docs/api.md What endpoints are available?
RAG Performance Tips
- Use Specific File Patterns for Faster Retrieval: Narrow down searches to specific directories or file types to enhance speed.
- Keep Chunk Sizes Moderate (512-1024 Tokens): Balance between context richness and retrieval speed.
- Use the
nomic-embed-textModel for Efficient Embeddings: Ensures quick and accurate embedding generation. - Leverage
maxChunkSizeandmaxBatchSizeSettings: Optimize these settings based on your hardware to improve retrieval performance.
Optimizing Your Workflow
Code Completion Best Practices
- Use Shorter Context Windows for Faster Completions: Reduces processing time without significantly impacting quality.
- Adjust Temperature Based on Task: Lower temperatures for precise code generation, higher for creative solutions.
- Configure Appropriate Debounce Delay for Your Typing Speed: Ensures that completions are timely and relevant.
Chat Optimization
- Use System Messages to Guide Model Behavior: Tailor responses by setting clear instructions in the
systemMessage. - Leverage RAG for Context-Aware Responses: Utilize RAG to provide the AI with relevant context from your codebase.
- Adjust
keepAliveBased on Usage Patterns: Optimize resource usage by configuring how long the AI remains active.
Resource Management
- Monitor VRAM Usage: Keep an eye on GPU memory to prevent bottlenecks.
- Use
numThreadsSetting Appropriately: Balance between performance and resource consumption. - Consider Model Switching for Different Tasks: Use smaller models for less intensive tasks and larger ones when needed.
Troubleshooting
Common Issues and Solutions
-
Slow Completions
- Reduce Context Length: Shorter contexts require less processing.
- Adjust
numThreads: Increase or decrease based on CPU availability. - Check VRAM Usage: Ensure your GPU isn’t overburdened.
-
Poor Quality Completions
- Adjust Temperature and Top_p: Fine-tune these parameters for better results.
- Verify Model Loading: Ensure the correct model is loaded and functioning.
- Check Context Window Size: Ensure it’s appropriate for your tasks.
-
RAG Issues
- Verify Embeddings Provider Configuration: Ensure the embeddings model is correctly set.
- Check Chunk Sizes: Optimize chunk sizes for better retrieval.
- Monitor Batch Size Settings: Adjust to match your hardware capabilities.
Conclusion
This setup provides a powerful, local AI coding assistant that can match or exceed cloud-based solutions. The combination of DeepSeek’s models with Ollama’s efficient infrastructure creates a responsive, private, and capable development environment.
Remember to:
- Choose Appropriate Model Sizes for Your Hardware: Align model complexity with your GPU capabilities.
- Configure RAG Settings for Optimal Codebase Understanding: Enhance the AI’s ability to reference and utilize your code.
- Fine-Tune Completion Parameters for Your Workflow: Adjust settings like temperature and debounce delay to suit your coding style.
- Monitor and Adjust Resource Usage as Needed: Ensure your system remains responsive and efficient.
Continue experimenting with configurations to discover your optimal workflow balance. Happy coding!